算法的设计和分析
Undecidable Problems
罗素悖论(Russell’s Paradox)是一个很著名的悖论:设集合 是由一切不属于自身的集合所组成(即 ),那 属于 吗?
我们通常用理发师悖论(The Barber paradox)去解释罗素悖论。假设城里只有一个理发师,且任何一个不能自己理发的人会由理发师帮他理发。定义 为所有被 理发的人的集合,则 。但是 是否成立呢?成立和不成立都会导致矛盾。
经典的停机问题(Halting problem)就是从以上的悖论中构造出来的。于是我们用 Undecidable Problem 去描述那些不存在算法能正确判定 yes/no 的问题。判定两个 CFG 是否同构也是不能解的。
下面介绍一下 Post Correspondence Problem。给出一个 dominos 集合,每一个 domino 的上下部分各印有一个字符串,且可以翻转。现在要找一个有限的 domino 序列(每一种 domino 可以重复选),使得上下部分各自连成的字符串完全相同。左图展示了 种 domino,右图是一个可行排列。

那么是否存在一种算法能判定一个 PCP 实例的解的存在性?答案是否定的。当字符集 时,PCP 是一个 Undecidable Problem。PCP 甚至可以模拟图灵机的计算过程。
Merge-Insertion-Sort
先从一个问题引入:有 个互不相同的数,最少需要几次比较才能排出它们之间的大小关系?
首先,基于比较 的排序算法的复杂度下界是 。这个结论可以用决策树(Decision Tree)证明:总共有 种可能的序列,每次比较最多排除掉一半,所以至少要 次。
可是归并排序也只需 次比较就能使数组有序,此问题不是解决了吗?并不是。注意,我们考查的是 精确步数,而非在大 意义下。目前,这个问题在很小的 下也未研究清楚。
一个经典且有效的策略是 Binary Comparison Sort:每次把第 个数二分插入前 个有序的数字里(其实就是插入排序)。总步数是 。
上述做法在 时就失败了。几乎所有算法都需要 步才能确定顺序,但最优解只要 步:
- 首先任意挑 个数字分两组比较,设比较完后的 个数字是
- 比较 和 的大小,不妨设 。
- 将 插入 这条链里,只需要 步。
- 将 插入 这条链里。因为我们知道 ,所以也只需要 步。
Merge-Insertion-Sort 从这个例子受到启发进行递归设计的,具体操作如下:
- 首先将数字分成 个组两两比较。如果是奇数那就多出一个数字。设比较完的序列是 ,以及可能存在单个
- 对于 这 个数调用一次小规模的 Merge-Insertion-Sort 使其有序。

- 依次把 序列插入到主链上。具体地,首先分别花 步把 (通过二分)插入到 的链上;然后花 步把 插入到链上;然后花 步把 插入到链上……
现在我们来分析一下 Merge-Insertion-Sort 的具体步数。
- 设 是 个数的比较次数,可知 ,其中 表示将 个数按上述顺序插入链中的方案数。
- 下面我们来计算一下 。在插链这步,如果把相同步数的分到同一组,那么这个序列是 ,前缀和数列 满足 。
- 若
- 注意到
- 最后我们可以得到
我们再来考虑一下这个问题的 Lower_bound。总共有 种可能的序列,通过决策树(Decision Tree)定理我们得到下界是 。
下面我们来感受一下 Binary Comparison Sort,Merge-Insertion-Sort 和 Lower_bound 的效果:
| 算法 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|
| LB | 5 | 7 | 10 | 13 | 16 | 19 | 22 | 26 | 29 |
| MI | 5 | 7 | 10 | 13 | 16 | 19 | 22 | 26 | 30 |
| BC | 5 | 8 | 11 | 14 | 17 | 21 | 25 | 29 | 33 |
Adversary Argument
除了 Decision Tree 外,我们有一个强有力的工具 Adversary 来分析一个算法的下界。它的核心思想是:Release the least information and change the scenario to make the algorithm work hard.
先来考虑一个 Find Second Maximum Element 问题。我们都知道,找最大值至少需要也仅需要 次比较;如果我们重复这个过程,在剩下数里面再找一个最大值,得到该问题的比较次数上界:
那么如何分析出下界呢?首先我们观察一个很有趣的结论:次大值只能在那些与最大值比较过的数字里产生。所以该问题的下界其实是 ,其中 是曾经与最大值比较过的数字。假设回答的策略已经确定,那么最终对下界分析产生影响的 其实是该策略面对所有算法后取得的最小值,即 。为了分析出原问题 更紧 的下界,我们要找到一种策略,使得它的 尽可能大 。
现在我们要借助 Adversary 分析出尽量大的 。考虑这样一种策略:
- 给每一个数字 一个“战胜指数” ,初始时 。
- 假设某一次询问的数对是 ,Adversary 采用的回答是:若 ,那么回答 ,且执行 ,反之亦然(这个策略有点像并查集的按秩合并)。
注意到,无论你用什么算法来给出 ,每次比完一组后, 都不可能超过原来的 倍,而最终时候最大值 必然满足 ,所以 至少经过了 次比较后才能确认。即该策略的 。顺着之前的思路,要确定次大值,必须把这些曾经输掉的数字之间再比试一次。所以得 Find Second Maximum Element 问题的一个比较次数下界是 。
再来考虑一个 Median 问题:有 个互不相同的数,最少比较几次可以知道这些数里的中位数?
显然排序问题的比较次数是其上界。那么下界是什么样的呢?想象一棵 个点的树,树边表示我们已知的大小关系。我们幻想的最优情况是:median 这个点成功地把其他点区分开了。即对于一个小于它的邻居,它子树下面也是递减关系;对于一个大于它的邻居,它子树下面也是递增关系。
称 为 Crucial Comparison,如果它满足 ,或者 。反之就是 Non-Crucial Comparison。可以发现,如果去对应那 个点的树,CC 是树边而 NCC 是非树边。
Adversary 提供这样一种策略:使每次询问得到的结果尽量都是 Non-Crucial Comparison。具体地,设状态 表示还未分配, 表示这个数已小于 Median, 表示这个数已经大于 Median。对于询问的 :
- 如果状态是 ,分配
- 如果状态是 或者 ,将 分配成余下那种状态。
重复这样的分配方案,直到 个 或者 被分配出去了为止。如果按这种方式分配,最终得到的树里至少有 条非树边。再加上 条树边,得 Median 问题的比较次数下界是
来看 Median 问题里 的例子。之前说过,排序的下界是 次,但 Adversary 提供更紧的 次的下界。事实上,只需 次比较的算法确实能构造出来:
- 先花 步决策出 。
- 此时我们知道 必然比中位数大,丢掉 。
- 把 和 拿去比较,再把大者和 去比较。花了 步可得 。
- 最后花 步比较 和 ,大者就是中位数。
我们再来设计一种 普适的算法 求解 Median 问题,使得比较次数尽量少。一般化问题,设 表示集合 里第 小的数,同时设 表示 时的 比较次数。
- 将 按每组 个划分,分别求中位数。这一步比较次数是 的。
- 递归调用 求这 个中位数的中位数 ,比较次数 。
- 以 为关键字将 划成两部分 。如果 不是中位数:
- 如果 就调用
- 否则调用
- 任何情况下 ,所以
可以用数学归纳法证明 。也就是说,Median 问题的比较次数上界是 。
再来看一个 Find Max and Min 问题。 一个很优秀的分治做法是:
- 设 表示 集合的最大值和最小值。
- 如果 ,只要比较一次就能返回结果。
- 若 ,将其划分为 和 两个集合,分别求 和 ,把两者的最大值求一个 ,把两者的最小值求一个 。所以步数 。
最后解得 。现在我们用 Adversary 证明这是下界。
定义四种状态 。其中所有数字都会经过 到 的转变,还有 个数字会经过从 到 的转变,总信息量是 。我们希望询问者知道的信息量尽量得少,具体决策如图:
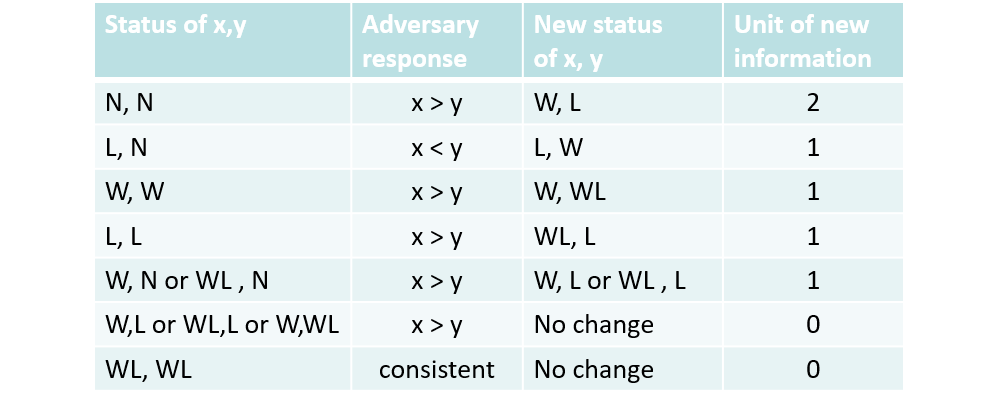
- 如果比较 ,被迫让其获得 信息量变成变成
- 如果比较 ,持续让 赢,获得 信息量变成
- 如果比较 ,保持,让其徒劳无获。
- 如果比较 ,被迫让其获得 信息量变成
至多有 组比较带来了 的信息量。剩下 的信息量每个至少消耗一次比较。所以不管以怎样的策略询问,比较次数都不会少于 ,即这就是该问题的下界。
再看一个 Find x in Matrix 问题:有一个 的数字矩阵,矩阵里的数字都互不相同,且每行从左到右和每列从上到下都严格递增。用尽量少的比较次数找到 ,每次返回 。
考虑这样一个算法:从右上角开始询问,假设当前的数字是 。若 就向下走,若 就向左走,这样总能找到 。可以发现,最坏情况下要走 次。
现在用 Adversary 证明这就是下界。
上述矩阵给出了一个形式化构造(以 举例)。任何一个 或者 都有可能被替换成 ,所以 必须和这些数字都比较一遍。那么如果是 的,得出下界是 。
再来看一个 Merge Sorted Sequence 问题。将两个长度为 的有序序列合并成一个有序序列,最少需要几次比较?直觉告诉我们,归并排序的 次比较最少。下面用 Adversary 来证明这一点。
构造数列 使得 当且仅当 (比如 )。最终合并完后的序列是 ,假设存在一个算法能在 步(或更少)完成,那么至少存在一个 满足:
- 如果 , 没有和 和 比较
- 如果 ,则 没有和 比较。
现在我们把 和 交换,依然符合题目条件,但是该算法失败了。所以 次是比较下界。
Unbound Searching
假设有这样一个定义在正整数域上的函数 :
如何用最少的步数来确定 的大小?
最先想到的肯定是二分,但是这个问题里 可能无限趋向于 。于是提出了下面这个算法:
定义 Binary search :
- 从小到大询问 (即 )直到
- 现在我们知道 ,即
- 在 上进行二分查找,需要 步。
- 总步数
可不可以做得更好呢?我们可以用迭代的方法更快地算出 !
定义 Double Binary search :
- 套用 去求出 ,需要 步。
- 重复 的步骤 ,总步数
那么对于 k-Binary Search :
现在还有一个问题:如何找出我们想要的 ?设 满足:
我们从小到大尝试 数列直到
Reduction
Reduction 是个经典的话题。来看一个经典的 Integer Distinctness Problem。
给出一个数的集合 ,要用尽量少的比较次数,判断其中是否有重复的元素。
显然可以通过 sorting 解决这个问题。神奇的是,我们可以反过来证明 sorting IDP。
- 假设 已经从小到大排好序了,一个结论是:任何解决了 IDP 的算法必然比较过所有 pair。证明很简单:如果 和 没有比较过,将改成 改成 。算法输出不变,但是结果和之前不同了。
- 现在我们开始规约。本来手里有一个 sorting 问题,我们先求解这个序列的 IDP 问题。
- 求解 IDP 过程中涉及了若干次比较。把这些比较的结果都保留下来,建成一个有向拓扑图,最后对其跑线性的拓扑排序。由结论 ,所有相邻的 pair 必然出现在图中,所以必然能恢复完整的 sorting 结果。
- 所以我们用了和求解 IDP 一样的复杂度,把 sorting 规约到了 IDP。
再来看一个连续规约的例子:3-SUM Collinearity Segment Splitting。
- 3-SUM 问题:有 个不同的数,是否能选出其中的三个数 使得
- Collinearity 问题:平面上有 个点,是否能选出三个共线的点。
- Segment Splitting 问题:平面上有 条线段,是否存在一条直线能将不触碰地将他们划成非空两部分。
3-SUM Collinearity 有两种证明方法。一是把原来 3-SUM 里的每个点 对应到平面上 这个点。 如果 ,充要于 ,反之亦然。二是把原来 3-SUM 里的每个点 对应到平面上的 三个点。如果 ,则 共线,反之亦然。注意这两个方法都要用到斜率,所以都有 三个数互不相同的前提。
Collinearity Segment Splitting 可以沿用上面的证明二。我们在 上画三条线,对于每个 ,在对应三个点处“开一个小洞”。这样如果 Collinearity 有解,我们就得到了穿过所有小洞的直线,反之亦然。
因为 3-SUM 是很多问题简化版本,对其的研究突破至关重要。可惜的是,人们已经证明:对于任何一个 , 不存在 的 3-SUM 解法。
3-SUM 还有一个变种问题 3-SUM’:选数时可以重复选,即 可以相同。看上去变得更难了?实际上它比 3-SUM 更简单,因为我们可以轻松构造出 3-SUM’ 3-SUM:对于 3-SUM’ 里的每个数 ,映射 3-SUM 里的 三个数(其中 是原数集里最大的数字)。
再来看一个厉害的 Reduction:矩阵乘法和矩阵求逆是可以相互规约的。这里只证明前者规约后者。对于矩阵乘法 ,我们可以花 的时间构造出以下 的矩阵。注意矩阵求逆后包含 这一项。
Flow and Match
Ford-Fulkerson 算法是最朴素的最大流算法:每次任意找一条增广路进行增广。值得注意的是,该算法可能永远也不会停止,下图就是一个例子。。更糟糕的是,该算法甚至没有收敛到最大流,因为
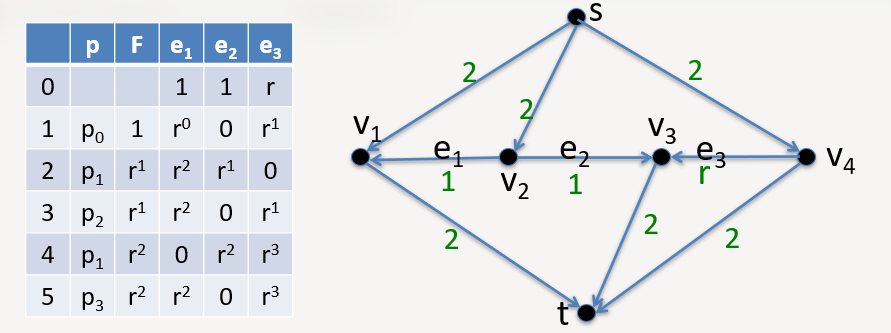
Edmonds-Karp Algorithm 算法改进了上述过程。它先用 BFS 对点进行标号,每次选择最短的增广路。一条增广路上至少存在一条边 满足它的流量等于本次新增的流量,我们称之为 critical edge(其实就是增广路上残余流量最少的那些边)。critical edge 会使边完全反向(不存在原方向的流量了),当它下一次又成为 critical edge 时,增广路的长度至少增加 。每条边最多只会成为 critical edge 次,一共有 条边,每次增广复杂度是 ,所以总复杂度是
我们熟知的 Dinic 算法其实是 EK 算法的多路增广版本。Dinic 引入了分层机制——每次把到终点距离相同的最短路径同时增广,使得复杂度降成 ,而实际速度也很快。下面我们来证明一下:把 Dinic 应用到匹配问题上最多只有 个 Stage。
- 我们用 表示从起点开始顺着流走 步能到的点的集合。
- 假设最终的最大流是 ,我们有 (想要流这么多,每一层至少需要这么多点)。
- 对以上不等式求和。假设起点到终点的距离是 ,则 。
- 如果 就已经证完了,因为每个阶段至少增加 的流量。
- 如果 ,根据以上性质,。每轮增广完后下次距离至少加 ,所以最多加 次。
知乎里 讨论了如何构造出让 Dinic 跑 的图。
说起匹配问题,还不得不提到一个 霍尔定理。对于左右各 个点的匹配问题来说:
右推左是显然。左推右可以反证:考虑网络流跑完的残量网络,取 为 割里所有左侧点 。
Computational Geometry
凸包这个话题想必大家都不陌生。
通过构造点 ,我们可以把排序问题规约到求凸包,也就证明了其下界是 。
因为凸包的计算几何里的应用很广,如何构建凸包是一个脍炙人口的话题。在算法竞赛里,我们一般用 sort +扫两遍分别求上下凸壳的方法,速度快代码短。下面再来介绍几种有趣的构建方法:
- Jarvis March - gift wrapping:从下面的点 开始,每次枚举一个点 使得 这条线段在所有点的右侧。把 加入集合并重复这一过程。这个算法很是直观啊,复杂度就是 。
- 我们同样熟悉的 Graham Scan 其实就是对上述算法的优化,用极角排序把复杂度降为 。
- Quickhull:初始时找到 最小和最大的两个点连上一条线 。线的两侧分别做一遍,每次找到一个距离线最远的点 ,连上 和 并重复这个过程。平均复杂度 ,最坏复杂度 。
- 分治算法:每次按 大小关系分成两半,各自求凸包并把凸包合并。复杂度 。
下面我们再来看一个 Line Segment Intersection 问题:给出平面上的 条线段,求它们两两的交点(如果有的话)。直接暴力是 的,但是如果交点很少,我们就想要找一个更快的做法。
维护一条垂直于 X 轴的 sweeping line(扫描线)。从左往右扫,保证扫描线左边的交点已经全找到了。这里有一个小结论:最近相交的两条线段,它们一定会与扫描线都有交点,而且这两个交点是 相邻 的。所以我们用平衡树按顺序维护所有与扫描线产生交点的线段。我们再用一个堆维护一些关键节点,包括 一条线段的终点位置 和 两条在扫描线上相邻线段的交点。每次弹出最近的关键节点(把扫描线移到那里),更新扫描线上(平衡树里)的点,同时也更新堆里的点。总复杂度是 , 是交点个数。
Voronoi Diagram
V 图是分析和处理平面图的一个有力的工具,而且他的定义也十分自然。
所谓 V图,就是把平面(无限或者有限)分割成若干个部分。初始时有 个互不相同的点 ,每一个区域 就是由所有到 最近的点构成。这个定义比较拗口,我们来看个直观的例子。
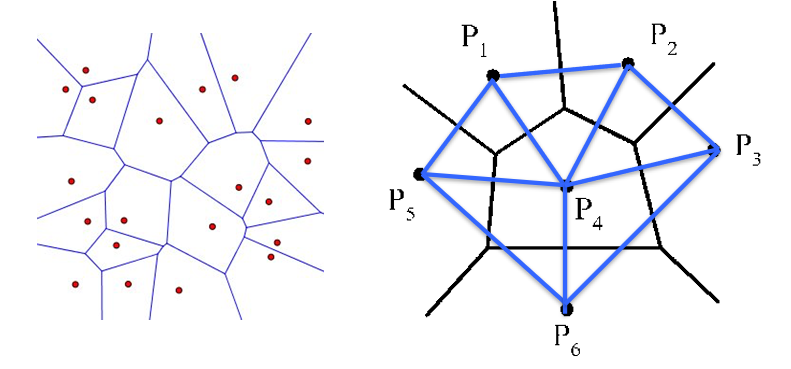
结合左图的例子我们还能发现,每一段区域的边界都是一组 的垂直平分线。如果我们在这些 之间连上线,就可以得到右图这个形状。没错,它就是外围 构成的凸包的三角剖分!
定理:若 ,V 图最多有 个顶点和 条边。
证明:假设有 个顶点和 条边。
- 欧拉定理:
- 注意一个顶点至少和三条边关联,所以
- 由以上两个式子即可推出 且
知道了 V 图的点数和边数都是 的,我们就可以放心地用 V 图来做各种分析了。
- 找到 个点里最近的 Pair:直接枚举 V 图三角剖分里的那些边。
- 求 个点的凸包:把外围的无限区域里的点顺次连接起来即可。
所以问题的关键是:我们如何高效地建出 个点 对应的 V 图?还是用我们的万金油:分治算法。每次合并都是线性的,所以 V 图可以 建出来。具体合并细节有点麻烦。
下面我们来看一个经典的 Art Gallery Problems:(凹)多边形内最少布置多少守卫才能看到所有位置。
注意这个问题已被证明是 NP-Hard 的,所以我们尝试求一些紧的界。首先一个显然的上界是 ,因为我们可以在三角剖分后每个三角形的中心放一个守卫。至于为什么 个点的(凹)多边形能剖分成 个三角形呢?可以用归纳法证明:
- 时是 个。
- 时,设 是最左边的点, 是它相邻的点。如果连接 后不与别的边相交,就把三角形 切下来归纳。否则我们在相交侧的点里找一个与 最近的点 ,用 把多边形切割成两半,每一半调用结论归纳。
现在我们再来证明一个更紧的上界。如果把多边形(任意一个)三角形剖分后的边也连上去,我们可以用对偶证明,新图的顶点是可以三染色的。更厉害的是,如果我们在三染色的任意一种颜色处放置守卫,均能覆盖整个多边形!那么挑一种出现次数最少的颜色,我们可以得到 Art Gallery Problems 的上界:。
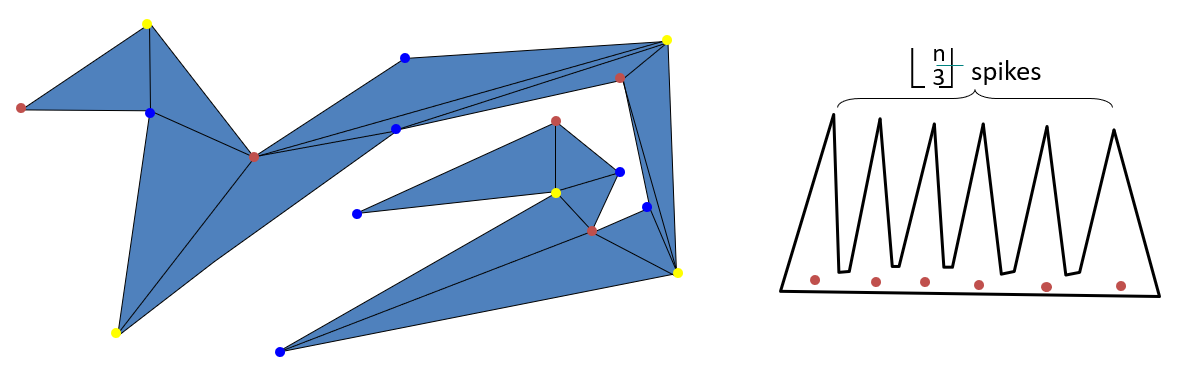
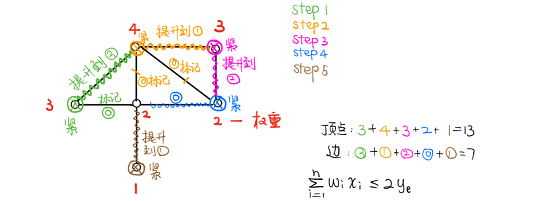
事实上我们还能构造出达到这一上界的多边形,见右图。
 wechat
wechat alipay
alipay