《编译原理》知识整理
整个编译的流程包括如下两个阶段:
- front end: scanner parser semantic analyzer source code optimizer
- back end: code generator target code optimizer
编译原理就是围绕这两个阶段展开的知识点。
词法分析 lexical analysis
Regular Expression
- Rules
- R* zero or more strings from L®: R(R*)
- R+ one or more strings from L®: R(R*)
- R? optional R: (R|ε)
- [abce] one of the listed characters: (a|b|c|e)
- [a-z] one character from this range: (a|b|c|d|e|…|y|z)
- [^ab] anything but one of the listed chars (Lex)
- [^a-z] one character not from this ranges
- The same language may be generated by many different regular expressions.
Finite Automata
- 包括 Transition,start state 和 accepting states
- 将 FA 用 Code 实现
- 如果直接按 state 进行 if-嵌套 地判断,程序会十分复杂。
- 一个更好的方法是:外层有一个大的 Case 语句,对不同的状态并列处理。
- DFA 转 NFA:
- 定义 为: 集合里的所有 state 连同它们的 -transitions 构成的集合。
- 原图中不同的点集对应新图中不同的点。把 设置成新图的出发点 。
- 对于新图上的每个点 ,枚举字符 ,对应的新集合为 如果原图的集合 在新图中没有出现过,就创建 ,然后从 到 连一条边。
- 重复 2-3 直到连完所有的点。
- RE 转 NFA:关注最外层的 RE 的 Rule,然后递归地转化 NFA
- DFA 的最小化原理:把原有状态划分为一些不想交的子集, 使得任何两个不同子集的状态是可区别的,而同一子集的任何两个状态是等价的。最后,让每个子集选一个代表,同时消去其他状态。
语法分析 Syntax Analysis
Context Free Grammar
- Derivatrion
- left recursive: the nonterminal A appears as the first symbol on the right-hand side of the rule defining A. e.g. ( doesn’t start with )
- right recursive: the nonterminal A appears as the last symbol on the left -hand side of the rule defining A. e.g. ( doesn’t start with )
- Parse Tree = concrete syntax trees 语法树
- Abstract Syntax Tree AST 抽象语法树
- 用 leftmost-child right-sibling 优化存储

- 用 leftmost-child right-sibling 优化存储
- ambiguous grammar: generates a string with two distinct parse trees.
- 左上是 ambiguous grammar,对应下面两种 parse,右上是改进。
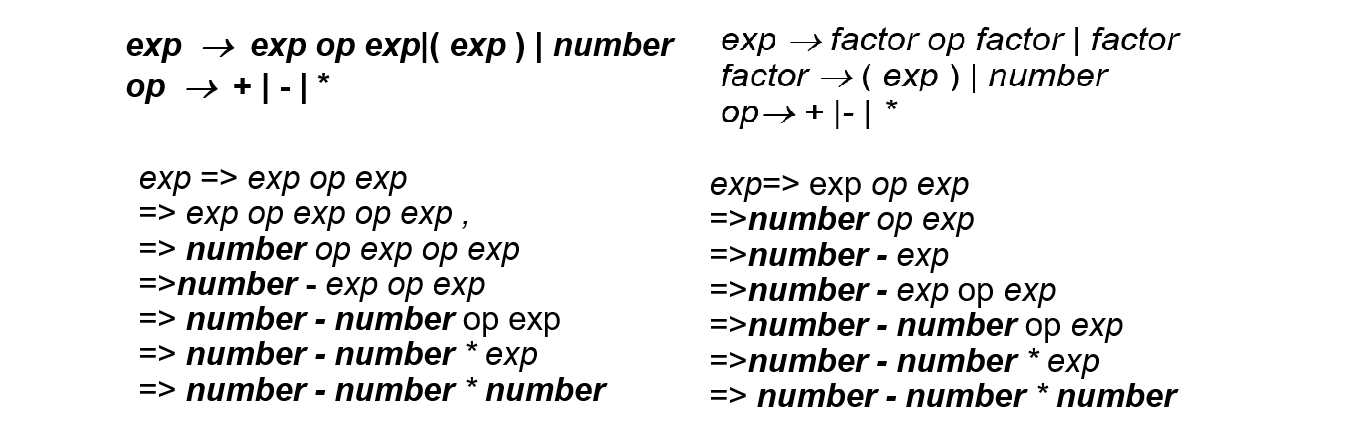
- 左上是 ambiguous grammar,对应下面两种 parse,右上是改进。
- The dangling else problem 解决方法
- 添加一个非终结符(变成 matched-stmt 和 unmatched-stmt),会使 else 尽量早地匹配。
- C 中要求加大括号。
- LISP 等语言要求必须给出 else-part。
- Ada 里用 end-if 去识别。
LL(1): Top Down Parsing
- 参考资料
- 就是从左向右扫描输入,维护一个栈,每次都把最左边的非终结字符用产生式代替。
- 一个自然的需求是,每当我们看见一个非终结字符,需要知道它是属于哪个产生式的。
- LL(1)文法的充要条件:对于任意 :
- 不存在 同时存在于 和 中。
- 和 最多只能有一个能导出 。
- 如果 ,那么 与 不能有交;反之亦然。
- LL(1)文法也可以定义成:其 Parsing table 每一格不存在多个转移。
- First 集合
- 表示能出现在 开头的终结字符的集合。
- 统计规则
- 直接收取:若存在 ,则将 放入
- 反复推送:若 ,把 的所有元素加入
- 为了处理 的情况,再引入 Follow 集合:
- 是可能在某些句型中紧跟在 右边的终结符号的集合。
- 统计规则
- 若 , 中除了 都放入 (直接根据定义)
- 若 或 且 中包含 ,则 的所有元素加入
- Parsing table M[N,T](N 是非终结符,T 是终结符)
- 构建规则:考虑 的转移
- 对于 中的每个元素 ,都将 添加到 M[U, a] 中。
- 若 ,对于 中的每个元素 都将 添加到 M[U, a] 中。
- 构建规则:考虑 的转移
- 消除左递归
- 若转移形如
- 则化简后的转移为
LR(k): Bottom-Up Parsing
- 代表从左至右分析(Left-to-right parse)、最右推导(Rightmost-derivation)、超前查看 个单词(-token lookahead)。
- 有一个栈和一个输入,输入中前 个单词是超前查看的单词。共有两种动作:
- 移进(shift):将第一个输入单词压入至栈顶
- 规约(reduce):选择一个文法规则 ,依次从栈顶弹出 ,然后将 压入栈。
- 的分析引擎
- 一个 状态 包含所有可能的(解析当下输入的)产生式,产生式右边用圆点(
.)表示解析到的位置。 - 定义两个基本操作 Closure(I) 和 Goto(I,X):

- 我们试图对所有可能的 状态 建立 DFA,边即为字符集(包含终结符和非终结符)。
- 我们实时维护了一个栈,记录了从头解析到现在曾到过那些状态。每次转移时要不是读入一个 终结字符 跳到一个新状态(将这些信息压入栈),要不进行规约弹栈得到一个 非终结字符,同时依据这个非终结字符在 DFA 上跳到新的状态并压栈。
- 根据 DFA 可以得到一张 的分析表。
- 如果一个状态某个时刻既可以移进当前字符、又可以规约(存在已经结束的产生式),就产生了 冲突。我们称这样的文法不是 文法。
- 一个 状态 包含所有可能的(解析当下输入的)产生式,产生式右边用圆点(
- 的分析引擎(Simple LR)
- 为了解决上述的冲突问题,我们引入范围更大的 。它提出了一个简单而有效的方案。
- 自动机状态的表示、移进和规约的操作都和 差不多,但让规约变得更严格了:若状态中存在已经结束的表达式 ,只有当下一个字符 满足 时才规约。
- 的分析引擎
- 只是一个必要条件而非充分条件, 试图找到更紧的规约条件。
- 定义项目 ( 是序列, 是终结符,称为搜索符):目前序列 在栈顶,且输入序列的开头可以解析成 。和 Follow 集合的思路类似,但是非终结符不再共享同一个集合。
- 一个状态依然对应了若干个项目,但闭包求法也变复杂了:

- DFA 的构建、分析表的构建和 类似,但是移进字符等于产生式对应的搜索符才能规约。
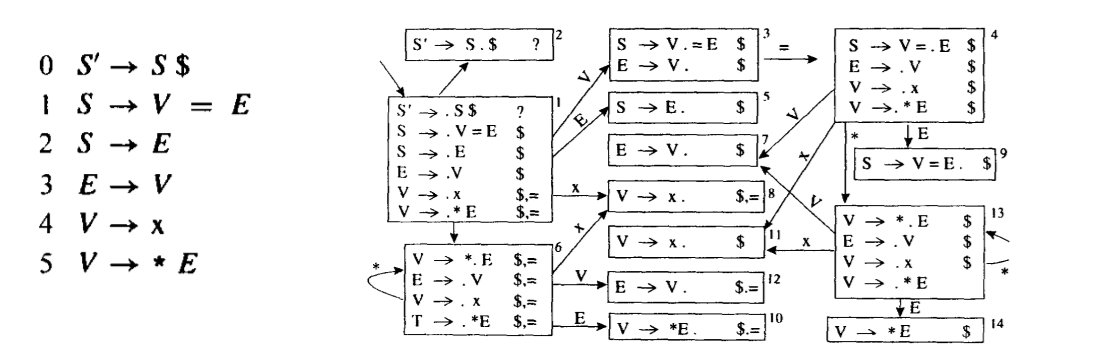
- 的分析引擎
- 的意思是超前查看(Look Ahead)的
- 的表太大了不方便, 会把产生式和圆点完全一样的状态 合并 成同一个,对应的搜索符合并。这样状态减少很多,可能会导致冲突。
- 以下是上面那个文法对应的 分析表和 分析表的比较。
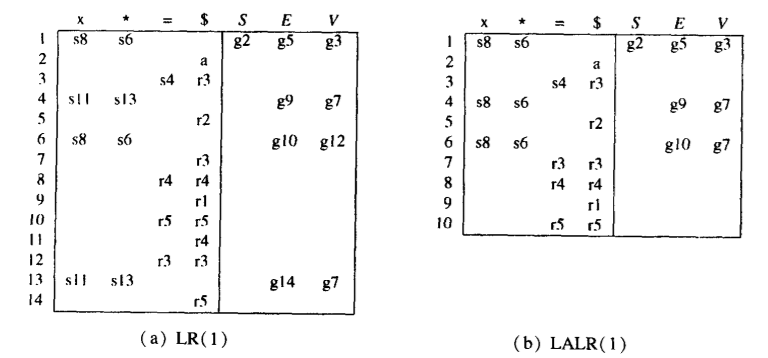
- 所有合理的程序设计语言都有一个 文法。
LL 和 LR 的关系总结
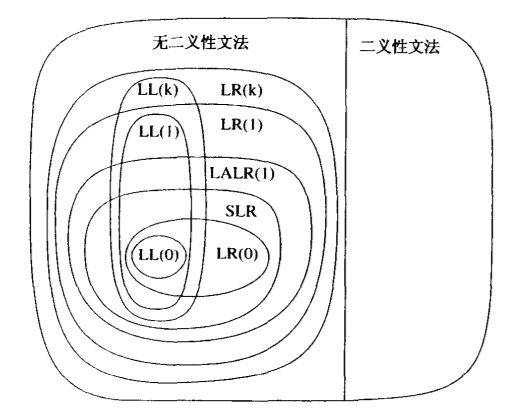
语义分析 Semantic Analysis
属性文法 Attribute Grammars
- Attributes: any property of a programming language construct
- Static attributes: fixed prior to the compilation process.
- Dynamic attributes: only determinable during program execution.
- Type checking: set of rules that ensure the type consistency of different constructs in the program
- An attribute grammar for attributes is the collection of all attribute equations or semantic rules of the following form, for all the grammar rules of the language.
- Dependency Graphs:必须是 DAG
- 在语法树(虚线)上画出属性的决定关系(实线)
- 属性分为两种:
- synthesized attributes 综合属性:“自下而上”传递信息,由其子结点的属性值确定。
- inherited attributes 继承属性:“自上而下”传递信息,一个结点的继承属性由此结点的父结点和/或兄弟结点的。
- 几条约束
- 不允许 的继承属性通过 的子节点来定义
- 允许 的综合属性依赖于它本身的继承属性来定义
- 终结符号有综合属性(来自词法分析)但是没有继承属性。
- L-attributed attribute grammar
- 对于所有产生式 满足: 只由 决定。
- 显然 S-attributed(仅由综合属性决定)属于 L-attributed。
- 对于 Top-down parser 来说,它可以有效决定所有属性(把继承属性放在参数里,把综合属性当做返回值传递上来)。
- 对于 Bottom-up parser 来说,LR parsers 只适合处理综合属性,但不能处理继承属性。
- LR parser 在解析属性文法时
- 在 parsing stack 基础上额外维护 Value stack: store synthesized attributes.
- Knuth [1968]:经过等价的语法修改后,任何继承属性都能转化成综合属性。
符号表 Symbol Table
- Symbol Table: Store the information about identifiers, like their scope or type.
- 维护方法
- linear list
- search tree (binary search trees, AVL trees, B trees)
- hash tables (most frequently in practice)
- open addressing:冲突时放到下一个格子。
- separate chaining:哈希挂链。
- 符号寻找方式:the most closely nested rule for block structure
Type check
- type equivalence
-
Structural equivalence:递归地检查,每一层的两个 type 的类型和组成(属性顺序)必须一致。
-
Name equivalence:他们的类型名(基本类型,自定义类型)完全一样才算一致。
t1:int; t2:int:则t1和t2算不同的类型。
-
Declaration equivalence 是 Name 的弱化版。
t2=t1establishing type aliases, rather than new types.1
2
3
4t1 = array [10] of int;
t2 = array [10] of int;
t3 = t1;
// t1 = t3,但是都不等于t2
-
Runtime Environments
- 三种运行环境
- Fully static environment FORTRAN77
- stack-based environment C/C++
- fully dynamic environment LISP
Activation Records
- 用于 Stack-based runtime environments,可以用 Activation tree 来分析
- 在不允许函数嵌套的语言(比如 C)中
- Frame pointer: a pointer to the current activation record to allow access to local variable.
- 在大多数编程语言中,可以通过 fp + static offset 来 access variables.
- Control(Dynamic) Link: a point to a record of the immediately preceding activation.
- Stack Pointer: a point to the last location allocated on the call stack.
- Frame pointer: a pointer to the current activation record to allow access to local variable.
- The calling sequence
- 计算函数参数,将它们放入新的 AR 里。
- 把新 AR 的 control link 设为当前 fp,再把当前 fp 移动到新 AR 里。
- 在新 AR 里保存 return address,调用函数。
- 当函数调用结束时
- 把新的 sp 设为 fp,把新的 fp 设为 control link
- 根据 return address 跳转到原 AR,并用 sp 不断弹栈。
- 注意有些函数可能会接受不同长度的参数。
- C 语言的策略是:将参数逆序放入 AR。这样我们总能用固定的 fp + offset 去访问每个参数。
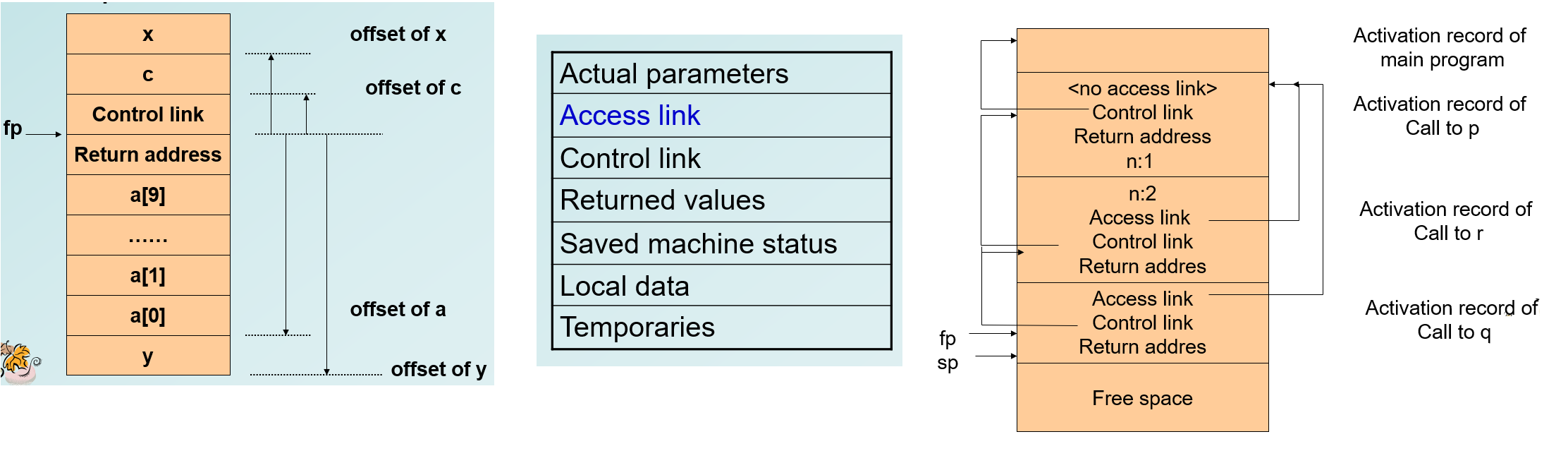
- 在允许函数嵌套的语言(比如 Pascal)中
- 增设 Access(static) Link:the defining environment of the procedure.
Heap Management
-
In most language, needs some dynamic capabilities in order to handle pointer allocation and de-allocation. Heap
- allocate and free
-
A standard method
- a circular linked list of free blocks
- 用 malloc 新建,用 free 释放
- 缺点:无法判断 free 是否合法;很容易变成一段一段的。
-
Automatic Management
- manual method:用户手动新建和释放
- garbage collection:回收那些没有被指的量
-
mark and sweep garbage collection
- no memory is freed until a call to malloc fails, which does this in two passes.
- Follows all pointers recursively,starting with all currently accessible pointer values and marks each block of storage reached.
- Sweeps linearly through memory.
- returning unmarked blocks to free memory.
- perform memory compaction to leave only one large block of contiguous free space at the other end.
-
stop-and-copy (two-space) garbage collection
Parameter Passing Mechanisms
- pass by value:传值引用
- pass by reference:传地址引用
- pass by value-result:传值进去,函数结束后再绑定回参数。
- pass by name:直接把参数的表达式传进去。

Code Generation
- Intermediate RepresentationA data structure that represents the source program during translation. Intermediate code can be very high level.
- Three-Address Code 三地址码
- 4 fields are necessary: one for the operation and three for the addresses
- Such a representation of three-address code is called a quadruple.
- 三地址码还有一种实现是:把 Instruction 编号也作为 temporary 存计算结果(这样就可以少开一个地址了)。缺点是,这样一段代码位移起来还要修改。
- P-Code
- 在 P-machine 上运行的码
- The P-machine consists of a code memory, an unspecified data memory for named variables, and a stack for temporary data, together with whatever registers are needed to maintain the stack and support execution.
- 一个
2*a+(b-3)的例子1
2
3
4
5
6
7ldc 2; load constant 2 (pushes 2 onto the temporary)
lod a; load variable a (pushes a onto the temporary)
mpi; integer multiplication (pops these two values from the stack, multiplies them (in reverse order), and pushes the result onto the stack.)
lod b; load value of variable b
ldc 3; load constant 3
sbi; integer subtraction (subtracts the first from the second)
adi; integer addition - P-code instructions require fewer addresses than Three-Address Code, less compact, and closer to actual machine code.
- From Intermediate Code to Target Code
- Macro expansion:逐句翻译
- Static simulation:等效替换
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
 wechat
wechat alipay
alipay
Related Articles
2023-07-27
算法的设计和分析
记录了我 2020.4-2020.6 在浙江大学上的《算法设计与分析》这门课的知识点。我会挑一些新奇有趣的、以前没见过的主题进行分享,可以把这篇文章和趣题摘记系列结合起来看。
2023-07-27
应用运筹学-线性规划应用
我在大三春夏学期上了张国川老师的《应用运筹学基础》这门课。张国川老师坚持板书讲解,课上干货满满,这篇文章是三分之一的课程笔记。

2023-07-27
CoSQL 数据集
记录了我 2020.3-2020.6 在浙江大学上的《机器学习》这门课的知识点。
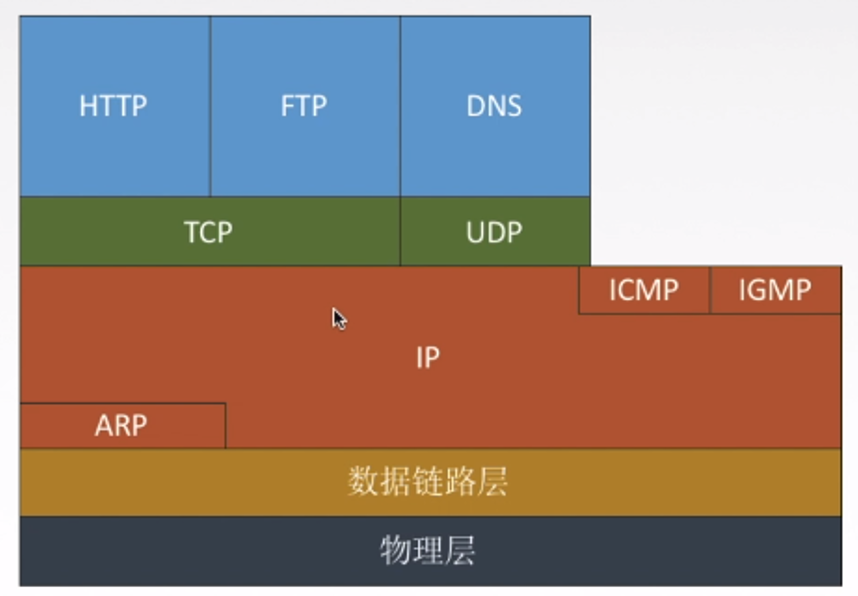
2021-09-05
《计算机网络》知识整理
记录了我 2020.3-2020.6 在浙江大学上的《计算机网络》这门课的知识点。

2020-06-30
《计算机组成》知识整理
记录了我 2019.3-2019.6 在浙江大学上的《计算机组成》这门课的知识点。
2020-06-30
《计算机视觉》知识整理
记录了我 2019.9-2020.1 在浙江大学上的《计算机视觉》这门课的知识点。