AI 发展指南
BERT
ChatGPT
Huggingface
Hugging face 相当于机器学习界的 github,目前已共享了超过 个预训练模型, 个数据集。
Hugging face 由三名法国人于 2016 年在纽约创办,第一个产品是一个聊天机器人。2018年,他们在 github 上开源了大名鼎鼎的 Transformers 库,迅速在机器学习社区火了起来。
LLM
大语言模型(Large Language Model)在近年来呈井喷式发展。Kaplan J 等人在 2020 年提出缩放法则(Scaling Law),给出的结论之一是:模型的性能强烈依赖于模型的规模(包括参数数量、数据集大小和计算量),最后的模型的效果会随着三者的指数增加而线性提高。这意味着模型的能力是可以根据这三个变量估计的。
涌现能力(Emergent Abilit) 是大模型的特点之一 。当模型规模在一定范围内(如 FLOPs 在 以内),能力并没有随着规模的提升而显著提高;而当规模超过一个临界值时(尽管没有改变结构),效果会马上提升。
**幻觉(hallucination)**是大模型的缺陷之一。幻觉指的是 LLM 生成看似合理但却虚假或有误导性的响应。目前普遍的看法为,经过校准的语言模型必然会出现幻觉,而与 Transformer 架构或数据质量无关。
自 2017 年特征提取器 Tranformer 发表以来,LLM 主要有三条发展方向:
| 发展方向 | 特征 | 简述 |
|---|---|---|
| BERT | Encoder Only | 自编码,适合做理解任务 |
| GPT | Decode Only | 自回归,适合做生成任务 |
| T5 | Encoder-Decoder | 综合了上述两点的优势,参数暴涨但潜力大 |
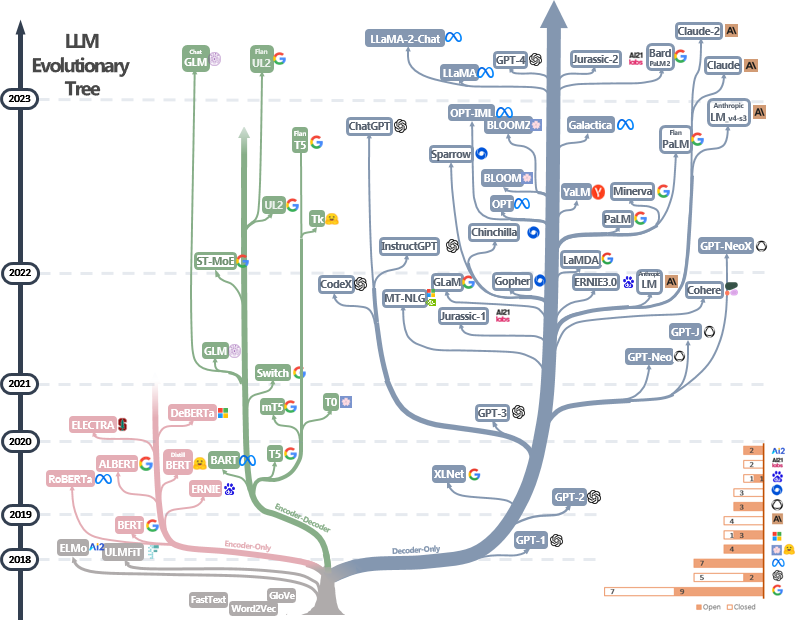
图源: https://github.com/Mooler0410/LLMsPracticalGuide
全球常见的大模型和大模型产品举例如下:
| 发布时间 | 单位 | 产品 | 参数量 | 上下文KB | 定位 |
|---|---|---|---|---|---|
| 2017.6 | OpenAI | GPT-1 | 117M | 0.5 | 聊天机器人 |
| 2019.11 | OpenAI | GPT-2 | 1.5B | 1 | 聊天机器人 |
| 2020.6 | OpenAI | GPT-3 | 125M~175B | 2 | 聊天机器人等 |
| 2022.2 | LamDA | 2B, 8B, 137B | 未开源模型 | ||
| 2022.3 | OpenAI | GPT-3.5 | ~600B | 4 | 聊天机器人等 |
| 2023.2 | Meta | LLaMA | 7B, 13B, 30B, 65B | 2 | 免费商用模型 |
| 2023.3 | OpenAI | GPT-4 | 1760B | 8, 32 | 聊天机器人等 |
| 2023.3 | Anthropic | Claude | 93B | 100 | 安全聊天机器人 |
| 2023.7 | Meta | LLaMa2 | 7B, 13B, 70B | 4 | 免费商用模型 |
| 2023.8 | Meta | Code Llama | 7B, 13B, 34B | 16 | 免费商用模型 |
| 2023.11 | Anthropic | Claude2 | 137B | 200 | 安全聊天机器人 |
| 2024.3 | Anthropic | Claude3 | Haiku、Sonnet Opus | 200 | 安全聊天机器人 |
中文社区的大模型情况如下:
| 发布时间 | 单位 | 产品 | 参数量 | 是否开源 |
|---|---|---|---|---|
| 2023.2 | 复旦大学 | MOSS | 16B | 开源 |
Prompt
Transformer
Transformer-VQ: Linear-Time Transformers via Vector Quantization
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 wechat
wechat alipay
alipay