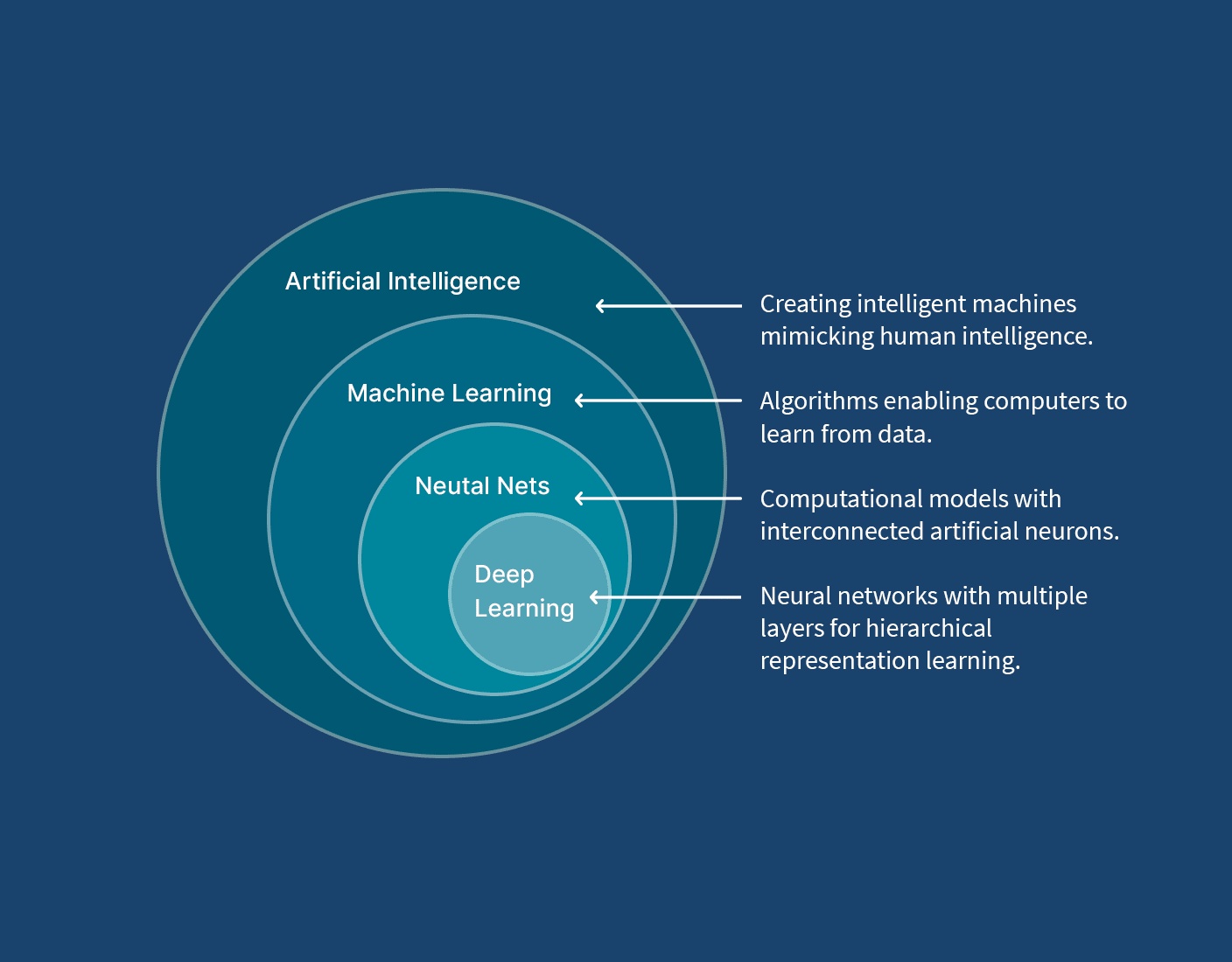
经典机器学习
综述
线性回归
线性模型(Linear Model):已知训练数据 ,学一个向量 使得预测函数为 。
线性回归(Linear Regression):用均方误差(Mean Squared Error)估价,即 。
推论:如果样本数小于特征数, 一定不满秩,即推不出最优解。
拓展:为什么用均方误差估价是合理的?
- 一个线性模型的实际效果记为 ,样本量充足时噪声 服从高斯分布 。
- 如果我们已经有了个模型,那么当前标签分布出现的概率是 。
- 我们希望找到一个模型使得 尽可能得大,用最大似然理论去估计,得出极大化 等价于极小化 MSE。
拓展:使用 惩罚项来缓解标准线性回归中的过拟合和多重共线性的现象。当 时优化函数是凸的,所以我们总能解出最优的解(即使是数值解)。但是当 时就没有那么好的性质了。
岭回归(Ridge Regression):特指 的 L2 惩罚项。解的系数会向零收缩,但不会完全变为零。
套索算法(LASSO):特指 的 L1 惩罚项。解会变得稀疏的,即很多维会被压缩到 。
逻辑回归:
贝叶斯决策理论
贝叶斯决策理论(Bayesian Decision Theory):基于贝叶斯公式进行有监督地预测。
- 先验(Prior):。获得新数据前,基于历史经验或知识对事件发生概率的初始信念。
- 似然函数(Likelihood):。在已知某个参数或状态的情况下,观察到新数据的概率。
- 后验(Posterior):。观察到新数据后,对事件发生概率的最新、最完整的信念。

最大似然决策(Maximum Likelihood Decision):直接根据 Likelihood 去预测标签。
- 隐含了所有类别的先验概率相同,即 。
最优贝叶斯决策(Optimal Bayes Decision Rule):用更准确的 Posterior 去预测标签,理论最优。
【待更新推导】
聚类
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
 wechat
wechat alipay
alipay
Related Articles

2020-09-03
深度神经网络下的流媒体技术
记录了我 2020.7-2020.8 在芝加哥大学暑研时,对 Server-Driven Video Streaming for Deep Learning Inference 的论文解读。

2025-07-21
探索 DeepSeek
本文将围绕 DeepSeek 分析其 AGI 的相关技术。

2020-07-16
解几何题调研
记录了我 2020.7-2021.3 在加州大学洛杉矶分校暑研时,对几何问题求解做的调研。

2025-09-07
大模型调研
大语言模型(Large Language Model)在近年来呈井喷式发展。本文试图针对 LLM 的过去技术和最新进展做一个汇总。
2020-04-07
感知-推理管道的鲁棒性
记录了我对 Improving Certified Robustness via Statistical Learning with Logical Reasoning 的论文解读。
2025-01-28
云上形式化验证论文走读
本文将概述几篇云上形式化验证的论文。本文关注的重点方向包括:可满足性模理论的工程实践;AWS IAM Policy;AWS IAM Access;Analyzer 产品和背后用到的技术,特别是 AWS 的内部服务 Zelkova。