大模型调研
大语言模型(Large Language Model)在近年来呈井喷式发展。
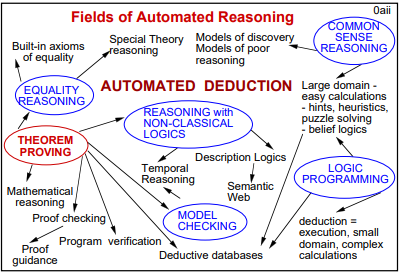
自 2017 年特征提取器 Tranformer 发表以来(Transfomer 解读可参考 这篇),LLM 主要有三条发展方向:
| 发展方向 | 特征 | 简述 |
|---|---|---|
| BERT | Encoder Only | 自编码,适合做理解任务 |
| GPT | Decode Only | 自回归,适合做生成任务 |
| T5 | Encoder-Decoder | 综合了上述两点的优势,参数暴涨但潜力大 |

图源:https://github.com/Mooler0410/LLMsPracticalGuide
LLM Architecture
知识蒸馏
混合专家模型
LLM Benchmark
Open LLM Benchmark:Huggingface 上针对开源大模型的榜单。
经典的大模型数据基准列举如下,部分提供训练集用于微调,部分则仅提供测试集。
| 数据基准名称 | 年份 | 测试集 | 简介 |
|---|---|---|---|
| Google-Proof Q&A | 2023 | 448 | PhD 级别的物理、化学、生物多选题 |
| Chinese Evaluation Suite | 2023 | 13948 | 涵盖 52 个学科四个难度的中文多选题 |
| Beyond the Imitation Game Benchmark | 2022 | 204 | 通过指标或程序化检验的多领域题目 |
| Massive Multitask Language Understanding | 2020 | 14079 | 包含 STEM 和人文社科知识的选择题 |
| General Language Understanding Evaluation | 2018 | 1063 | 包含九类自然语言生成的任务 |
LLM Concept
奶奶漏洞 grandma exploit:网友发现在和大模型对话时,如果要求其扮演自己已经过世的祖母,就可以绕开模型的安全护栏机制,套取包括 Win11 序列号在内的敏感内容。这个漏洞最早可追溯到 2023 年 4 月。
思维链 Chain of Thought:要求模型在输出最终答案之前,显式输出中间逐步的推理步骤。CoT 是一种简单有效的 Prompt 技术,在复杂场景(如算术推理、常识推理、符号推理等)里效果很好。
涌现能力 Emergent ability:当模型规模在一定范围内(如 FLOPs 在 以内),能力并没有随着规模的提升而显著提高;而当规模超过一个临界值时(尽管没有改变结构),效果会马上提升。
幻觉 hallucination:LLM 生成看似合理但却虚假或有误导性的响应。目前普遍的看法认为,经过校准的语言模型必然会出现幻觉,而与 Transformer 架构或数据质量无关。
缩放法则 scaling law:模型的性能强烈依赖于模型的规模(包括参数数量、数据集大小和计算量),最后的模型的效果会随着三者的指数增加而线性提高。由 Kaplan J 等人 2020 年提出。
投机解码 speculative decoding:针对自回归解码(autoregressive decoding)推理时串行输出 token 的场景进行加速。投机解码是 drafting 和 verification 两个阶段的循环:先用一个独立小模型串行生成一定长度的 token 序列,再把序列的每个前缀都并行过一遍大模型,从第一个不能被大模型接受的位置重复上述操作。投机解码的本质是用并行算力换低时延,大模型的总推理量不变,但额外增加了小模型的推理量。
LLM Framework & Tools
| 工具名 | 介绍 |
|---|---|
| Hugging Face | 大模型开源共享中心,目前已共享了超过 个预训练模型, 个数据集 |
| Langchain | 专为构建基于大模型的应用程序设计(尤其是 RAG)的开源框架 |
LLM Training
量化技术
并行技术
数据并行 Data Parallelism:把数据集拆分成几个切片,每个切片被分配到一个设备上。每个设备将持有一个完整的模型副本,并在所分配的数据集切片上进行训练——相当于沿批次维度对训练过程进行并行化。注意反向传播后,各设备的梯度要进行 AllReduce 聚合,使得模型参数保持同步。
张量并行 Tensor Parallelism:将一个操作里的张量沿特定维度分成 N 块进行计算,每个设备只持有整个张量的 1/N。需要引入额外的通信来确保结果的正确性。
典型的张量并行实现:Megatron-LM(1D)、Colossal-AI(2D、2.5D、3D)。
流水线并行 Pipeline Parallelism:将模型按层分割成若干块,每块都交给一个设备。在前向传播过程中,每个设备将中间的激活传递给下一个阶段;在后向传播过程中,每个设备将输入张量的梯度传回给前一个流水线阶段。优点是增加了训练吞吐量,一缺点是训练设备容易出现空泡(bubble),导致计算资源的浪费。
典型的流水线并行实现:GPipe、PipeDream、PipeDream-2BW、PipeDream Flush(1F1B)。
LLM Inference
检索增强生成(Retrieval-Augmented Generation):在生成过程中引入外部知识库(如文档、数据库),通过检索相关片段辅助生成,提升事实准确性。最初由 Patrick Lewis 于 2020 年发表在 NIPS 上。
微调(fine-ture):在预训练的大型语言模型基础上,针对特定任务或数据集进行进一步训练,通过较小规模的目标任务数据集使模型更好地适应特定任务。
参数高效微调(Parameter-Efficient Fine-Tuning):即仅微调部分参数,适合于资源受限的环境或多任务学习。
- 选择性方法(selective):只微调原始 LLM 参数的子集。
- 添加性方法(additive):添加一些可训练的层或参数来调整基础模型。
- 适配器(adapaters):在基础模型中加入一些可调整参数的组件、模块来使模型适应下游任务。
- 软提示词(soft prompts):通过某种方式达到给输入加入提示词的效果,从而适应下游任务。
- 重新参数化方法(reparameterization-based):创建原始网络权重的新低秩转换来减少要训练参数。

图源:Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
| 常见 PEFT 方法 | 概述 |
|---|---|
| LowRank Adaptation | 保持原有模型不变,对差值低秩分解: |
| Quantized LoRA | 将原模型权重量化为 4-bit 精度再应用 LoRA |
| Adapters | 在 Transformer 层插入小型神经网络模块,冻结原参数 |
| Prompt Tuning | 在输入序列加入可训练的软提示(Soft Prompt)向量,训练参数非常少 |
| Prefix-Tuning | 在 Transformer 层的 KV 矩阵前添加可训练前缀向量 |
LLM Products
Hugging face:
全球基础大模型举例如下(专用于数学、编程等细分领域的模型不列入表格):
| 时间 | 单位 | 产品 | 参数量 B | 开源 | 上下文 KB | 特色架构 |
|---|---|---|---|---|---|---|
| 2017.06 | OpenAI | GPT-1 | 0.117 | 0.5 | ||
| 2019.11 | OpenAI | GPT-2 | 1.5 | 1 | ||
| 2020.06 | OpenAI | GPT-3 | 0.125~175 | 2 | ||
| 2022.02 | LamDA | 2, 8, 137 | ||||
| 2022.03 | OpenAI | GPT-3.5 | 4 | |||
| 2023.02 | Meta | LLaMA | 7, 13, 30, 65 | 是 | 2 | |
| 2023.03 | OpenAI | GPT-4 | 1760 | 8, 32 | ||
| 2023.03 | Anthropic | Claude | 93 | 100 | ||
| 2023.07 | Meta | LLaMA2 | 7, 13, 70 | 是 | 4 | |
| 2023.08 | Alibaba | Qwen | 1.8~72 | 是 | 8, 32 | |
| 2023.11 | Anthropic | Claude2 | 137 | 200 | ||
| 2023.12 | Gemini | |||||
| 2024.01 | Deepseek | Deepseek MoE | 16.4 | 是 | 4 | MoE |
| 2024.01 | Deepseek | DeepSeek LLM | 7, 67 | 是 | 4 | LLaMA |
| 2024.02 | Gemini 1.5 Pro | 1000 | MoE | |||
| 2024.02 | Alibaba | Qwen1.5 | 0.5~72 | 是 | 32 | |
| 2024.03 | Anthropic | Claude3 | 200 | |||
| 2024.04 | Meta | LLama3 | 8, 70 | 是 | 8 | LLaMA |
| 2024.05 | OpenAI | GPT-4o | 128 | |||
| 2024.05 | Deepseek | Deepseek V2 | 16, 236 | 是 | 32, 128 | MoE |
| 2024.06 | Alibaba | Qwen2 | 0.5~72 | 是 | 32, 128 | |
| 2024.06 | Anthropic | Claude 3.5 | 200 | |||
| 2024.07 | Meta | LLama3.1 | 8, 70, 405 | 是 | 128 | |
| 2024.09 | OpenAI | GPT-o1 | 128 | CoT, RL | ||
| 2024.09 | Alibaba | Qwen2.5 | 0.5~72 | 是 | 128 | |
| 2024.12 | Gemini2.0 Flash | 32->1000 | ||||
| 2024.12 | Meta | LLama3.3 | 70 | 是 | 128 | |
| 2024.12 | Deepseek | Deepseek V3 | 671 | 开源 | 128 | MoE |
| 2025.01 | Deepseek | DeepSeek R1 | 671 | 开源 | 128 | MoE, RL |
 wechat
wechat alipay
alipay