《数据库系统》知识整理
《数据库系统》这门课的 Workload 很大,期中和期末分别有一个 Project,还有个硬核的期末考试:
Relational-algebra Expression
- 基本功能
- 并,差
- :笛卡尔积
- : 将 重命名为 。
- :选取 中符合条件 的记录。
- :投影 中的部分属性。
- 拓展功能
- 交
- 自然连接
- 带条件连接
MySQL 语法
约束(Constraints)
- 普通约束
not nulluniquecheck()create assertion <name> check()
- 键约束
- 单一主键
id numeric(4,0) primary key - 复合主键
primary key(...) - 外键
foreign key (name1) references name2- 可以添加
on delete/update cascade来定义 transaction
- 可以添加
- 单一主键
函数和过程(Functions and Procedures)
- 函数
- 定义
1
2create fuction <fuc_name>(参数列表) returns (返回参数列表)
return(返回值列表)return前后可以加begin和end- 调用
1
select * from table(<fuc_name>(参数列表))
- 过程
- 定义
1
2
3create procedure <fuc_name>(in name varchar(20), out ans integer)
select count(*) into ans from dict
where dict.name == name- 调用
1
2declare cnt integer;
call <fuc_name>('Bob', cnt)
常用语法
-
基本语法
- 定义变量:
declare n integer - 赋值:
set A = B; - 删除表 中的属性 :
ALTER TABLE r DROP A - 选择时:
select distinct/all不能重复/需要重复 Group by- 注意:Attributes in select clause outside of aggregate functions must appear in group by list.
- 如:
1
2
3SELECT branch_name, avg(balance) avg_bal
FROM account
GROUP BY brach_name- `HAVING ...` 用来对 `group by` 之后的结果选择- 按某属性排序:
order by ...结尾加:asc升序desc降序。 where中可以加的表达式:AND,OR,NOT,BETWEEN ... AND ...- 字符串
- 连接:
|| - 正则表达式:
where A LIKE ...%匹配任意字符_匹配任意字符串
- 连接:
- 集合操作
UNIONINTERSECTEXCEPT
- 一些函数
avg, sum, count, min, max- 用
GROUP BY来聚合 Having ...一般跟在GROUP后面用来描述条件
with ... as ...局部定义(类似于函数)- 修改表 中数据
- 定义变量:
-
分支结构
1
2
3
4
5
6if boolean_expression
then compound_statement
else if boolean_expression
then compound_statement
else compound_statement
end if -
循环结构
- for
1
2
3
4
5
6
7declare n integer default 0;
for r as
selet budget from department
where dept_name == 'Music'
do
set n = n - r.budget
end for- while
1
2
3while boolean_expression do
statements;
end while- repeat
1
2
3
4repeat
statements;
until boolean_expression
end repeat
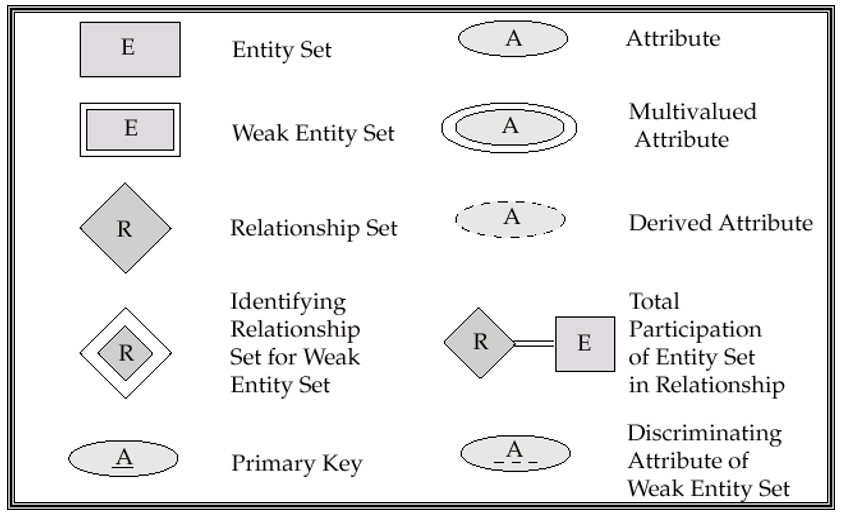
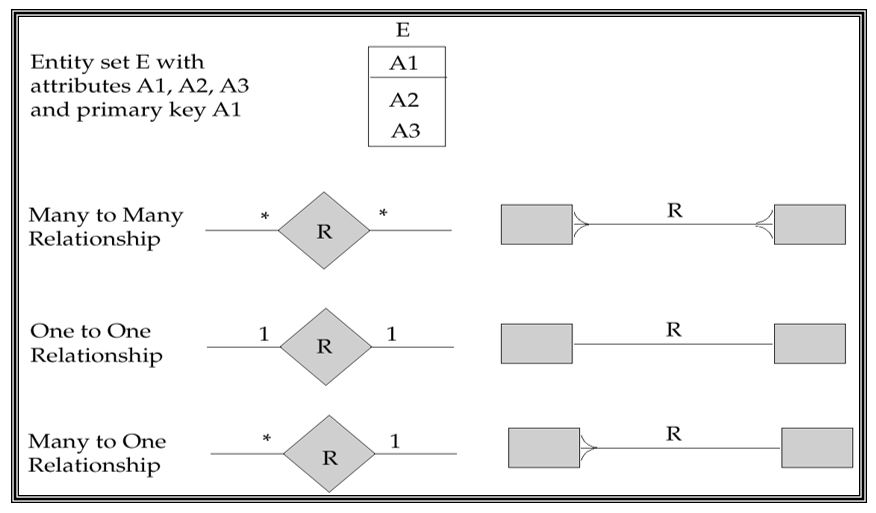
ER模型

范式理论
- 第一范式(First Normal Form,1NF)
- 定义:所有 Domain 都是不可分的(atomic)。
- 关系型数据库要求都是满足 1NF 的。
- 函数依赖(Functional dependency)
- 函数依赖 在 上成立,当且仅当对于所有关系 ,
的值确定了,那么 的值也确定了。
- 举例:比如主键 K 能推出所有属性。
- 如果一个函数依赖集 对于所有 成立,则称 在 上成立。
- 能推出的极大函数依赖集,称为 的闭包(closure),记作 。
- 函数依赖 在 上成立,当且仅当对于所有关系 ,
- 函数依赖集闭包
- Armstrong’s 公理

- 推导

- 属性 在 下的闭包记为 。
- 求 的方法
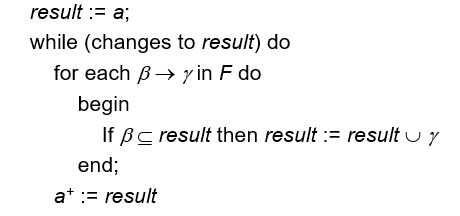
- 求 的方法
- 检验
- 是否是
super key。 - 是否成立。
- 是否是
- Armstrong’s 公理
- 正则覆盖(Canonical Cover)
- 函数依赖集 的“最小表示”。
- 三种去重方式:
- 能被别的函数依赖直接推出的。
- 在箭头左侧的对象,可能可以变少。
- 在箭头右侧的对象,可能可以因为拆开后重复导致变少。
- 无关属性(Extraneous Attributes ):
首先设 。- 称 是 的无关属性(),如果 能推出
- 检验:
- 称 是 的无关属性(),如果 能推出 。
- 检验:
- 称 是 的无关属性(),如果 能推出
- 正则覆盖过程:每次去掉无关属性。
- 分解(Decomposition)
- 将 Schema 分解成 ,必须满足 。
- 无损连接分解(Lossless-join decomposition):
对于 Schema 的所有关系 ,满足
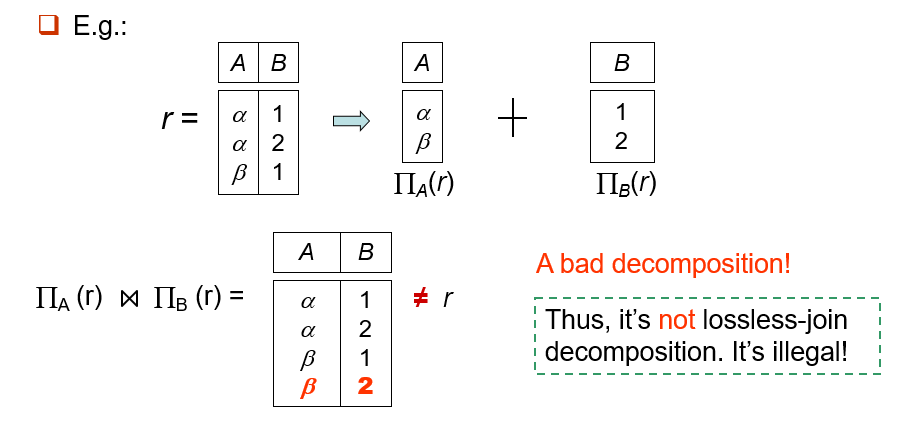
- 二元分解的判定:以下依赖在 至少有一个成立:
- 二元分解的判定:以下依赖在 至少有一个成立:
- 依赖保持(Dependency preservation)
- BCNF(Boyce-Codd Normal Form)
- 定义:对于 里的每一个非 trival 的 ,满足 是 里的 super key。
- 注意:只检验 和检验 是在 处等价,在分解 处不等价。
- Third Normal Form (3NF)
- 定义:对于 里的每一个非 trival 的 ,至少满足以下的某一条:
- 是 里的 super key。
- , 包含于 的一个 candidate key 里。
- 一定存在一种满足函数依赖、所得关系都是第三范式的无损连接分解。
- 定义:对于 里的每一个非 trival 的 ,至少满足以下的某一条:
索引
- Two basic kinds of indices:
- Ordered indices
-
Clustering(Primary) index(聚集索引)Secondary index
-
Dense index (稠密索引)Sparse index (稀疏索引)Sparse index只能用于顺序文件, 而dense index可以用于顺序和非顺序文件,如构成索引无序文件。
-
Secondary Indices(辅助索引)
-
- Hash indices
- Ordered indices
- B+ 树
- 实时满足的性质
- 对于 阶
B+树,每个节点拥有最多 个孩子, 个键值。 - 对于叶节点,储存 条记录。
- 任意一个非根非叶节点,有 个孩子。
- 如果根不是叶节点,至少要有两个孩子。
- 对于 阶
- 高度和size的估算

- 实时满足的性质
查询
- Measures of Query Cost
- cost:
- – time to transfer one block. (≈ 0.1ms)
- – time for one seek. (≈ 4ms)
- Cost for b block transfers plus S seeks:$b \times t_T + S \times t_S $
- cost for selection:
- 不使用
index- linear search: block transfers, 1 seek
- binary search:
block transfer+seek
如果不是key,block transfer要额外加上
- 使用
index- 用
key:block transfer+seek。 - 非
key同样也要加上 个block transfer.。
- 用
- 非等值查询一般用
linear search。 - 查询 Conjunction :根据耗时最少的条件找到记录并
check剩余。 - 查询 Disjunction :直接暴力查询,除非所有条件都有
index。
- 不使用
- cost for join:
-
Nested-Loop Join

- 最坏情况:
transfer,seek - 最好情况:
transfer,seek
- 最坏情况:
-
Block Nested-Loop Join

- 最坏情况
transfer。 - Let the relation with smaller number of blocks be outer relation.
- 最好情况:与上同理。
- 最坏情况
-
Indexed Nested-Loop Join
inner relation要有索引。- 枚举每一个 ,用索引去找符合要求的 。
- 代价:
-
Merge-Join(排序归并连接)
-
transfers,seeks
-
-
Hash-Join Algorithm
- 对 用外层哈希对 和 进行
Partition。 - 对每一个 进行
in-memory hash. - 对每一个 ,找到对应的 。
- 称为
build input, 称为probe input。 - 一般 $n = \lceil \frac{b_s}{M}\rceil * f f = 1.2$。
- 代价大概是
- 如果 ,进行
Recursive partitioning。
- 对 用外层哈希对 和 进行
-
- cost:
- Cost Estimation
- Statistical Information
- : number of tuples in a relation r.
- : number of blocks containing tuples of r.
- : size of a tuple of r.
- : blocking factor of r — i.e., the number of tuples of r that fit into one block.
- : number of distinct values that appear in r for attribute A; same as the size of .
- If tuples of are stored together physically in a file, then: $$ b_r = \lceil \frac{n_r}{f_r} \rceil $$
- Selection Size Estimation
- Statistical Information
事务(Transaction)
- 概念:a unit of program execution that accesses and possibly updates various data items.
- 在
transaction期间数据可以不一致,结束后必须一致。 - 四个特性:
- Atomicity.
- Consistency.
- Isolation.
- Durability.
- Transaction state

-aborted:roll back结束后返回到的初始状态。 - The shadow-database scheme
- 始终指向正确的数据库。
- 每次
update时新开一个new copy来更新。commit了后再指向新的。
- Concurrent Executions(并发)
Schedules- indicate the chronological order in which instructions of concurrent transactions are executed.
Serial schedule(串行调度):必能保证一致性,但是低效。
Conflict Serializability(可串行化)- 若2个操作是有冲突的,则二者执行次序不可交换;若2个操作不冲突,则可以交换次序。
- 如果
S可以通过交换次序到达S',称它们conflict equivalent. - 如果
S是等价于serial schedule,称为conflict serializable.
View Serializability
- Recoverability
Recoverable schedule— if a transaction reads a data item previously written by a transaction , then the commit operation of appears before the commit operation of .recover会导致Cascading rollback.Cascadeless schedules— reads a data item previously written by , the commit operation of appears before the read operation of .
并发控制(Concurrency Control)
| . | S | X |
|---|---|---|
| S | T | F |
| X | F | F |
-
Lock-Based Protocols
Exclusive (X) mode: 只允许事务 T 读取和修改,其他任何事务都不能读取、写入和加锁,直到 T 释放。Shared (S) mode: 允许 T 读但不能修改,其他事务只能加 S 锁但不能加 X 锁,直到 T 释放。deadlock:双方都施加过 S 锁,想申请 T 锁时都要等待对方释放。strict two-phase locking事务结束前不能释放锁。
-
Graph-Based Protocols
- If then any transaction accessing both and must access before accessing .
Tree Protocol- 只有 锁。
- 事务 第一次可以给任何点加锁,之后给点 加锁时必须保证 的父亲目前被 锁住。
- 一个
item可以在任何时候被解锁,但不能重新再上锁。
- 优缺点
- 保证了
conflict serializability,防止了deadlock。 - 不保证
recoverability,增加了无用的lock。
- 保证了
-
Multiple Granularity(多粒度)
- 描述成一个树结构

- 意向锁
Intention-shared(IS,共享型意向锁)Intention-exclusive(IX ,排它型意向锁)Shared and intention-exclusive(SIX,共享排它型意向锁)
- Compatibility Matrix

- Transaction Ti can lock a node Q, using the following rules:
- The lock compatibility matrix must be observed.
- The root of the tree must be locked first, and may be locked in any mode.
- A node Q can be locked by Ti in S or IS mode only if the parent of Q is currently locked by Ti in either IX or IS mode.
- A node Q can be locked by Ti in X, SIX, or IX mode only if the parent of Q is currently locked by Ti in either IX or SIX mode.
- Ti can lock a node only if it has not previously unlocked any node (that is, Ti is two-phase).
- Ti can unlock a node Q only if none of the children of Q are currently locked by Ti.
- 意向锁
- 描述成一个树结构
恢复(Recovery)
- Log-Based Recovery
- 语法
<Ti start>,<Ti commit>,<Ti abort><Ti, X, V1, V2>X 从 V1 变成了 V2(在输出操作前)<Ti, X, V>将 X 以值 V 输出。checkpoint <L1, L2 ...>设立断点,将所有数据保存下来
- 分类
- Deferred Database Modification(所有写操作在
commit后进行) - Immediate Database Modification(后来的讨论都是针对它)
- Deferred Database Modification(所有写操作在
- 先进行
undo操作(有start无commit)再进行redo操作(有start有commit) recover时,只有那些在最近一次checkpoint里或者之后开始的事务,才需要对其redo或者undo。- 并发恢复


- 语法
- ARIES:a state of the art recovery method
XML
<tagname>...</tagname>嵌套时必须严格匹配- XML 主要用于数据传输
- 元素(Element)
- 元素可以拥有一些属性(attribute)
- 用
name = value标注

- 元素中还可以定义 子元素(Subelement)
- use attributes for identifiers of elements, and use subelements for contents.
- 用
- 元素可以拥有一些属性(attribute)
- 用命名空间来防止变量名重复
 - 用
![CDATA[...]]套起来的是不套用XML语法的纯字符串 - Document Type Definition (DTD)
- 不含有类型(全以字符串储存)
- 语法
<!ELEMENT element (subelements-specification)><!ATTLIST element (attributes)>
- ELEMENT 定义规则
- ELEMENT 支持正则表达式
 - Attribute 定义规则

- ELEMENT 支持正则表达式
- XPath
- Result of path expression: set of values that along with their containing elements/attributes match the specified path.
- 查询 []
/bank-2/account[balance > 400]:Returns account elements with a balance value greater than 400./bank-2/account[balance]:Returns account elements containing a balance sub-element.
- 选择 attribute @
/bank-2/account[balance >400] /@account_number:Returns the account numbers of accounts with balance > 400.
- 并操作 |
- 跳过一级目录
// ID和IDREF- 可以给attribute一个唯一的
ID值,这样如果有个地方有一个IDREF,就可以实现联系和跳转。 IDREFS可以建立与 0 或 多个ID的联系。
- 可以给attribute一个唯一的
- XQuery
- 基本语法

- FLWOR Syntax

- join 操作
- 这句话等价于

- FLWOR Syntax
- 基本语法
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
 wechat
wechat alipay
alipay
Related Articles
2023-07-27
算法的设计和分析
记录了我 2020.4-2020.6 在浙江大学上的《算法设计与分析》这门课的知识点。我会挑一些新奇有趣的、以前没见过的主题进行分享,可以把这篇文章和趣题摘记系列结合起来看。
2023-07-27
应用运筹学-线性规划应用
我在大三春夏学期上了张国川老师的《应用运筹学基础》这门课。张国川老师坚持板书讲解,课上干货满满,这篇文章是三分之一的课程笔记。

2023-07-27
CoSQL 数据集
记录了我 2020.3-2020.6 在浙江大学上的《机器学习》这门课的知识点。
2021-09-05
《编译原理》知识整理
记录了我 2020.3-2020.6 在浙江大学上的《编译原理》这门课的知识点。
2021-09-05
《计算机网络》知识整理
记录了我 2020.3-2020.6 在浙江大学上的《计算机网络》这门课的知识点。

2020-06-30
《计算机视觉》知识整理
记录了我 2019.9-2020.1 在浙江大学上的《计算机视觉》这门课的知识点。




