应用运筹学-线性规划的基本理论
原计划基于 TSR 学长的博客 补充知识点的,由于《应用运筹学基础》将“上课笔记整理”也作为了考核方式之一,于是我把 TSR 学长的部分内容也结合进来了。这篇文章是系列之二,还有两个系列分别是:
凸集、凸函数、凸优化
凸集:任取 和 满足 ,称集合 凸集(Convex Set)。
- 凸集的交仍然是凸集。
- 如果没有 的条件,称集合 仿射集(Affine set)。
凸函数:对于定义在凸集 上的函数 ,若对于 有 ,那么称 是凸函数(Convex Function)。
- 延森不等式(Jensen’s inequality):若 是凸函数,
- 定理:凸函数的局部最优就是全局最优。
- 假设 是局部最优点, 为全局最优点,则 。
- 由于 为凸函数,那么对于点 有 。
- 取 ,就有 ,说明 在 的邻域内且比它优,矛盾。
- 凸函数的判定条件:
- 一阶判定条件:设 在凸集 上一阶可微,则该函数为凸的充要条件是:对于 ,都满足 .
- 二阶判定条件:设 在凸集 上二阶可微,则该函数为凸的充要条件是:对 ,都满足 。
凸优化:优化 。其中 是凸函数, 是仿射函数。
- 定义拉格朗日函数 :$ \mathbf{R}^{n} \times \mathbf{R}^{m} \times \mathbf{R}^{p} \mapsto \mathbf{R}$, $ L(x, \lambda, v)=f{0}(x)+\sum_{i=1}^{m} \lambda_{i} g_{i}(x)+\sum_{i=1}^{p} v_{i} h_{i}(x)$
- 最优解 满足 KKT 条件
- 原始条件:
- 拉格朗日函数梯度为 :
- 对偶约束:
- 互补松弛条件:
线性规划的定义
线性规划定义:

- 左边形式的问题被称为线性规划(Linear Programming)
- 由于仿射函数既是凸函数又是凹函数,所以优化问题是 min 还是 max 问题不大;常数 对优化问题的解没有影响,一般也可以去掉。这就变成了中间的这个优化函数。
- 对于 这个约束,可以通过添加非负变量将其松弛成等式。所以我们总能将线性规划转成右侧的形式。右式也称为线性规划的典则形式。
极点:若 无法表示为凸集 内某两个元素的凸组合,称 是极点(extreme point)。
- LP 问题的可行域实际上是很多超平面的交,最后组成的应该是一个超多面体。
- 极点就是超多面体的“顶点”。可以证明,若最优解有解,必然取在极点上:
- 假设最优点 严格在凸集里面。任取一条与凸集交在 和 的直线。因为是线性规划问题, 点处的函数值一定是 点和 点的线性组合。所以 和 中,至少有一处的函数值是大于等于 的。
- 我们可以重复上述步骤,把最优点一步一步约束到顶点上。比如在三维中,我们先将其“规约”到凸壳的表面上,最后“规约”到凸壳的边和点上。
基可行解:我们讨论 有解且行满秩的情况(如果不满秩就去掉线性相关的限制条件)。设 是一个 的矩阵,根据线性代数的知识,我们可以从 中选出最多 列线性无关的列向量,其它列向量都和它们线性相关。我们把这 个列向量调整到前面去,把 分成两部分:.容易构造出 的一个解:,称这种解为基可行解(Basic Feasible Solution)。显然,基可行解至多有 种。
- 定理1:每个极点都对应着一个基可行解,且每个基可行解都对应着一个极点。
- 定理2:最优解一定可以在基可行解处取到。
单纯形法
单纯形法(Simplex Method)(以 模型为例)
- 将 中的基变量消成单位矩阵,并把目标函数基变量的系数都消成 。
- 以某种策略找一个 的非基变量 入基。
- 依次考察 的行,确定一行 使得 最小(对于 最紧的限制)。
- 拿第 行去消,把每一行的 以及目标函数的 都消成 。即第 行的基变量出基。
- 重复步骤 直到检验数全大于 .
单纯形表(Simplex Tabuleau)
- 变量分成基变量和非基变量:设 , ,
- 显然我们有 且
- 通过简单的线性变换有:
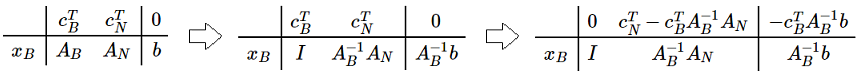
- 这其实就是单纯形法的形式化迭代过程
评价
- 变换的本质是:在满足约束的限制下,用不同的非基变量组合来表示目标函数。
- 当非基变量的检验值均 时取到最大值。我们可以想象成,目标函数就是由这些非基变量决定的,它们目前都取了 ,而且任意变量的微小增长都会导致结果变劣。
- 单纯形正确性证明
- 设最终的检验数是 (均小于 ),对应的解是 ,最优解是 。
- 令 ,我们有
- 那么 ,则
- 我们知道 ,又 ,所以 ;又 ,所以 ,那么 ,说明 并没有比 更优。
- 在非退化情况下,单纯形法一定可以停止。因为每次迭代都会让答案更优一点,访问的基可行解空间是不会重复的。而基可行解数量又是有限的,所以算法一定可以停止。
- 可以证明,如果按字典序的顺序选取 ,单纯形算法一定可以停止。
单纯形法的初始可行解
初始可行解
- 若单纯形的约束是 ,初始可行解可以取 .
- 若约束是 时,我们可以通过加入松弛变量 使得 ,这样 是初始可行解。这里存在一个问题: 是我们添加进去的变量——我们希望 能全部出基。
大 M 法(Big M Method)
- 对不为 的 进行“惩罚”。将目标函数改为 。如果 是一个足够大的正数, 就会在 这个“严厉的惩罚”之下变成 。
- 取多大很难说,且取得过大会影响精度。
两阶段法(Two-Phase Method)
- 添加了 后,我们考虑一个新的线性规划:约束不变,改成优化 这个函数。一组显然的初始可行解是 .
- 如果这个优化问题的最优解的目标函数值不为 ,则原问题无可行解;否则我们就找到了原问题的一组可行解。我们再以这个可行解为起点,利用单纯形法求出原问题的最优解即可。
- 由此可以发现,线性规划的可行解和最优解求解难度相同。
思考:对于 这个模型,如果突然多了一个 的条件怎么办?
- 添加一个松弛变量 :
- 此时会发生一个问题: 和 至少有一个会取负号,不符合约束。
- 怎么办呢?再引进一个变量 :
- 至此, 是新问题的一个可行解,直接套大M法或二阶段法求解。
对偶定理与对偶单纯形法
线性规划的对偶
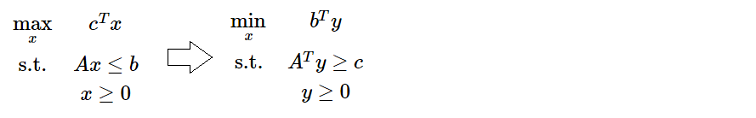

对偶定理
- 弱对偶定理 (Weak Duality):设 和 分别是原问题和对偶问题的可行解,则 。证明:由 的可行性我们有 ,即 ,两边同乘以 有 ;由 的可行性还有 ,那么 ,合起来就是 。
- 最优性:若 和 分别是原问题和对偶问题的可行解,而且 ,那么 和 分别是原问题和对偶问题的最优解。
- 可行性:若原问题无最优解(可以取无穷大),则对偶问题无可行解;若对偶问题无最优解(可以去无穷小),则原问题无可行解。
- 强对偶定理 (Strong Duality):若原问题(或对偶问题)有有限最优解,那么对偶问题(或原问题)也有有限最优解,且二者最优解相等。通过单纯形法的计算过程来辅助证明。
- 互补松弛定理 (Complementary Slackness):若 与 分别是原问题和对偶问题的可行解,以下两点等价:
- 和 分别是原问题和对偶问题的最优解;
- 且 。
对偶单纯形法步骤(以 模型为例)
- 取一组检验数全都 的基。
- 找一个 (一般找绝对值最大的)行 ,将非基变量 出基。
- 我们想让某个非基变量从 变成大于 来增加 。在这一行中,找一个 的 使得 最小(这样 消完目标函数后检验数依然全都 ),让 入基。
- 重复步骤 直到约束右侧的值均 。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
 wechat
wechat alipay
alipay
Related Articles
2023-07-27
应用运筹学-线性规划应用
我在大三春夏学期上了张国川老师的《应用运筹学基础》这门课。张国川老师坚持板书讲解,课上干货满满,这篇文章是三分之一的课程笔记。
2023-07-27
算法的设计和分析
记录了我 2020.4-2020.6 在浙江大学上的《算法设计与分析》这门课的知识点。我会挑一些新奇有趣的、以前没见过的主题进行分享,可以把这篇文章和趣题摘记系列结合起来看。

2023-07-27
CoSQL 数据集
记录了我 2020.3-2020.6 在浙江大学上的《机器学习》这门课的知识点。
2021-09-05
《计算机网络》知识整理
记录了我 2020.3-2020.6 在浙江大学上的《计算机网络》这门课的知识点。
2021-09-05
《编译原理》知识整理
记录了我 2020.3-2020.6 在浙江大学上的《编译原理》这门课的知识点。

2020-06-30
《计算机组成》知识整理
记录了我 2019.3-2019.6 在浙江大学上的《计算机组成》这门课的知识点。




